W poprzednim felietonie pisałem, jak zrobiono nowe odczyty rejestratora dźwięków CVR feralnego lotu smoleńskiego i dlaczego są lepsze technicznie, niż poprzednie. Podam i dziś kilka dodatkowych ilustracji. Ponieważ jednak mamy w Polsce nadmiar pomysłów, jak prowadzić poprawnie odczyty (a czasami nawet: jakie treści powinny zostać odczytane), to może należałoby najpierw zobaczyć, co robi się na świecie z tego rodzaju nagraniami. Są proste pytania, nie ma tylko prostych odpowiedzi: Kto i jak powinien stenogramować CVR? Kto ma identyfikować głosy? I w końcu, jaka jest pewność, że rozpozna się mówiących? Proponuję przyjrzeć się, jak to było robione w kraju, a jak jest robione w UE i Ameryce: kim są i co robią analizujący kopie CVR, czym się różni analiza dla komisji wypadkowej od pracy dla Temidy? Koniec końców, okazać się może, że polskie podejście nie jest wcale najgorsze! AR T I C U L A T ION - Analiza widma angielskiego słowa 'wymowa' do 8 kHz • www.iasforensics.com
AR T I C U L A T ION - Analiza widma angielskiego słowa 'wymowa' do 8 kHz • www.iasforensics.com
Specyfika i różne cele końcowe odczytów CVR
Rekordery dźwięku (CVR=cockpit voice recorder) są jednymi z najważniejszych źródeł danych o wypadkach lotniczych. Większość wypadków polega przynajmniej częściowo na błędach popełnianych przez załogę, a jak doszło do błędów, to pomagają wyjaśnić CVR-y. Czasami można też odczytać w nagraniach akustyczne dowody awarii samolotu. Lot 427 US Air w 1994 r. zakończył się śmiercią wszystkich 132 osób na pokładzie (szczęśliwym trafem nie doszło do spadku na centrum handlowe) po tym, jak nastąpiła awaria Boeinga 737. W wyniku m.in. badania CVR, przeprojektowano serwomechanizmy i stery pionowe tych samolotów. (Nota bene, w dochodzeniu udowodniono, że rekorder zapisuje dźwięk wydarzeń w strukturze samolotu odległej od kokpitu; przenosi się on tak, jak to miało miejsce w PLF 101, dziesiątki metrów poprzez metal, dlatego m.in. słychać uderzenia skrzydeł w smoleńskie drzewa).
Zapisy CVR różnią się znacznie od innego typu materiałów dowodowych w śledztwach: rozmów telefonicznych i różnego rodzaju podsłuchów. Po pierwsze, zapis CVR zawiera bardzo dużo zwrotów i skrótów z dziedziny awiacji, nie znanych potocznie. Po drugie, CVR jest korelowany z innymi zapisami wypadkowymi, głównie z zapisami parametrów lotu - co pozwala lepiej zinterpretować dźwięki i wypowiedzi, jak i zrozumieć, dlaczego pojawiły się w ściśle określonych momentach lotu zapisane w rekorderach parametrycznych (MSRP64, FDR/TAWS, jeśli chodzi o wypadek lotniczy pod Smoleńskiem dn. 10.04.10). Z pewnością to komplikuje samą analizę, ale daje w końcu pełniejszy obraz przyczyn i przebiegu katastrof. Sam zapis CVR nie jest jednak wystarczający do orzekania o przyczynach katastrofy.
Zbieranie w całość wątków śledztwa, by uzyskać odpowiedzi na zasadnicze pytania o przyczyny i winnych wypadkowi należy, odpowiednio, do komisji badania wypadków i prokurtur+sądów. Mimo, że te pierwsze mają inny cel (zmiany w przepisach i w technologiach, zapobiegające przyszłym wypadkom) niż te drugie (orzeczenie winy), to badaniu CVR przyświeca dokładnie ten sam cel, jakim jest uzyskanie maksymalnie czytelnego i pewnego transkryptu i identyfikacji mówców. W przeciwnym razie, zachodziłoby niebezpieczeństwo błędnego określenia ewentualnej winy osób, jak i błędnego zrozumienia czynnika ludzkiego w wypadku. Zatem przy rozbieżnych celach końcowych dochodzeń, i różnych wymaganiach formalnych co do osób zajmujących się nagraniami, celem bezpośrednim wszystkich odczytów powinno być to samo. Ale praktyka jurydystyczna i sprawy techniczne nie zawsze współgrają.
Jeśli chodzi o katastrofę smoleńską, to wiemy, że są spore różnice w jakości technicznej starych i nowych odczytów smoleńskiego CVR. Teraz załóżmy po prostu, że nagrania i opracowania cyfrowego danych dokonano i staje przed nami pytanie: jak przeprowadzić dalszą analizę, to znaczy jak najlepiej wykonać stenogram i identyfikację głosów. Kto i jak ma to robić, w jakim stopniu należy odszumiać uzyskane oryginalne nagranie.
Metody polskie - dawne odczyty, nowe wątpliwości
Dźwięk z lotu kończącego się wypadkiem lotniczym zazwyczaj odczytuje laboratorium policji lub instytut ekspertyz sądowych, na wniosek odpowiednich do śledztwa organów. Ze względu na wspomnianą specyfikę nagrań CVR, w takich odczytach powinny uczestniczyć osoby znające nie tylko metody transkrypcji rozmów, ale i osoby rozumiejące procedury i wyrażenia lotnicze.
W przypadku śledztwa smoleńskiego, jak wspominałem w poprzednim felietonie ( Dr French I presume), nie jest jasne, jak dobrze wypełniły to wymaganie laboratoria CLKP i KIES (ten ostatni instytut na wniosek wojskowej prokuratury okręgowej, WPO, w 2011-2012 r.). Wspomniałem też wcześniej o wątpliwości co do bardzo małej liczby (1-2) osób biorących udział w transkrypcjach i identyfikacji. Również miałbym kilka pytań dotyczących stopnia odszumiania zastosowanego przez IES; zbiory z ich nagraniami noszą nazwę korekcja_*, co sugeruje, że do odsłuchów używano być może tylko odszumionych nagrań. To byłoby błędem.
Problemy odszumiania
Potencjalny problem w tym, że nie istnieją obecnie metody odszumiania nagranego z zakłóceniami tekstu mówionego, gwarantujące statystycznie poprawienie jego zrozumiałości. Jedyne co można łatwo uzyskać, to usunięcie irytujących "linii widmowych", wąskich pasm częstotliwości pochodzących z bardzo głośnej awioniki tupolewa pod podłogą kokpitu, silników, klimatyzacji, czy w końcu z magnetofonu MARS, spowoduje, że odczyt będzie dużo mniej męczący.
Te sprawy są dopiero od niedawna intensywnie badane. Loizou (2013) w rozdziale 12.3 zatytułowanym "Comparison of enhancement methods: speech intelligibility" porównał wyniki zrozumiałości nagrań testowych wypowiedzi mężczyzny (próbkowanych z f=25 kHz, po czym zredukowanych do częstotliwości 8 kHz), przy ustalonym poziomie sygnału do szumu (dla kilku rodzajów zakłóceń: od sali dworcowej do wnętrza samochodu, jak i dwóch stopni względnego natężenia - 0 i 5 dB), po zastosowaniu nowoczesnych metod odszumiania dźwięku. Metod było osiem/trzynaście, w zależności od tego, co chciano zbadać konkretnie: trzy algorytmy subtraktywne (odejmujące części widma krótkookresowego uznane za szum - stosowane są w popularnych programach do obróbki dźwięku), dwa algorytmy oparte o metodę podprzestrzeni (met. dekompozycji osobliwej SVD i in.), trzy filtry typu Wienera (jeden z nich to metoda wavelet-threshold), oraz pięć zaawansowanych algorytmów odszumiania opartych o modele statystyczne (np. adaptacyjne zastosowanie tzw. Bayesa z różnymi metodami oceny jakości wyników). W każdym przypadku fragmenty zawierające mowę w nagraniu były wyszukiwane także przez programy. Testy odsłuchowe prowadzono w laboratorium Dynastat Inc. w Teksasie z pomocą 32 dorosłych odsłuchujących.
Wyniki tego dużego programu porównawczego są ciekawe i niepokojące. O ile subiektywna ocena jakości nagrania prawie zawsze podnosiła się znacznie po odszumieniu (czyli łatwiej się słucha nagrań odszumionych i wydają się one dużo lepsze), o tyle obiektywnie zmierzony procent poprawnie odczytanych słów angielskich był niemal bez wyjątku albo mniejszy niż w nagraniu nieodszumionym, albo niemal taki sam. Wyjątkiem był specjalny rodzaj szumu (wnętrze samochodu, jeden z 8 testowanych rodzajów zakłóceń) potraktowany jednym z rodzajów adaptywnych filtrów Wienera. Uśrednione po rodzajach szumu wyniki tego jedynego mogącego poprawić zrozumiałość mowy algorytmu były jednak dokładnie neutralne, w przypadku szumu dworca kolejowego pogarszał bowiem zrozumiałość mowy. Trudno byłoby zatem rekomendować na podstawie tych badań jakikolwiek algorytm. Tym bardziej, że zapisy rosyjskiego CVR są bardzo specyficzne, jeśli chodzi o zakłócania (kilka nałożonych rodzajów szumu i nierównomierności przesuwu taśmy), a nikt podobnych nagrań naukowo, w powyższy sposób, nie badał.
Wiadomo jednak z dotychczasowych odsłuchów amatorskich, że jest dość łatwo tak "odszumić" nagranie smoleńskie, że pojawiają się dziwne rezultaty (nie mówię tu o odwracaniu i dużym zwalnianiu biegu taśmy, to zupełnie osobny rodzaj 'śledztwa inaczej'). Prawdopodobnie jest to związane z próbami przesadnego podkręcania parametrów niedoskonałych algorytmów, które niechcący "czyszczą" część cennej informacji. Mózg ludzki interpretujący słyszane dźwięki jest wysoko wyewoluowanym organem. Potrafi nieraz dokonać separacji źródeł dźwięku oraz pominąć zakłócenia dużo sprawniej, niż obecne metody komputerowe.
A zatem, jeśli odszumianie, to z umiarem. Unikniemy wtedy mocnego tzw. szumu muzycznego, wprowadzanego do nagrania przez większość dostępnych programów.
Automatyczna identyfikacja osób?
Od razu powiem, że to samo odnosi się do zdolności automatycznej identyfikacji mówców przez algorytm komputerowy - tu jednak metodyka polska była moim zdaniem zawsze poprawna: nie próbowano jej w żadnych dochodzeniach smoleńskich.
Jest to ciekawy i rozwojowy kierunek badań, ale znajdujący się jeszcze w stadium eksperymentalnym. W r. 2015 BM.I (austriackie MSW) opublikowało krótki artykuł. Dr Sylvia Moosmüller, ekspert w zakresie fonetyki akustycznej w instytucie badań dźwiękowych Austriackiej Akad. Nauk, mówi tam, że policja używa zasadniczo metod fonetyki audytywno-akustycznej, jako że systemy automatyczne, zwłaszcza w przypadku dużych różnic warunków technicznych nagrań, dają niewystarczające rezultaty i mogą być wykorzystane najwyżej jako pomoc przy odsłuchach. Jednym z wiodących twórców metody automatycznej identyfikacji mówców jest dr Andrzej Drygajlo, pracujący w Szwajcarii na politechnice lozańskiej. Osobom interesującym się tematyką porównywania i rozpoznawania osób na podstawie nagrań polecam gorąco nową książkę dającą dobry przegląd obecnego stanu tej dziedziny (Neustein & Patil 2012, "Forensic Speaker Recognition", por. cytowaną literaturę). Zawiera ona artykuł przeglądowy dra Drygajlo.
Algorytmy komputerowe mają jeszcze za słabą zdolność rozpoznawania mówców, gdy nagrania porównywane są robione w inny technicznie sposób i w niepokrywającym się kontekście (jak i stanie emocjonalnym mówiącego). Rozpoznają w niektórych testach poprawnie tylko rzędu 40 procent mówiących i to w niezbyt zniekształconych nagraniach. Gdyby nie wspomniane różnice warunków nagrania, mogłyby rozpoznać 78% nagrań poprawnie. Jest też jeden hiszpański system software'owy (IntelliVox) dopuszczany do użytku w niektórych sądach, ale to jeszcze długo nie będzie standardowe narzędzie takie, jak edytory dźwięku dające możliwość zwalniania nagrania i odszumiania ich.
Polskie metody - nowe odczyty
Nowy odczyt CVR dokonany był w 2014 r., a opublikowany w kwietniu 2015 r. w wersji jeszcze nie końcowej. Trochę więc ryzykowne jest formułować wnioski na temat tego odczytu, gdyż obecnie są tymczasowe. Wiadomo jednak, jaka była z grubsza metodyka pracy biegłych prokuratury i to nam dziś w zupełności wystarczy, bo nie interesują nas tu konkretne wyniki w rodzaju: kto i co powiedział w jakieś minucie i sekundzie. Taśmę, zgodnie z oświadczeniem NPW i WPO, badały dwie grupy:
(i) Grupa odsłuchowa, 7 osób w której znajdują się osoby związane z lotnictwem (także, w przeszłości z pułkiem specjalnym lotnictwa transportowego, w którym latał PLF 101), jak i osoby nie związane z lotnictwem. Ten zespół, spełniający po raz pierwszy bezkontrowersyjnie podstawowy wymóg znajomości tematyki lotniczej, miał dokonać lepszego, niż poprzednio odczytu nośnika magnetycznego i na podstawie opracowanego przez siebie, komputerowo opracowanego nagrania, stworzenie niezależnego nowego transkryptu rozmów i dźwięków.
Praca trwała miesiącami i ze względu na mniejsze zmęczenie słuchu warto było stosować odszumianie - ale tylko pod warunkiem częstego sprawdzania, czy nie da się więcej zrozumieć w nagraniu nieodszumionym (tak właśnie robiono w WPO). Do wielokrotnych odsłuchów używano profesjonalnego, ale nie eksperymentalnego pod żadnym względem oprogramowania, umożliwiającego analizę odsłuchową dźwięku, jak i ogląd w czasie realnym spektrogramów krótkookresowych. Grupa nie dokonywała porównania z próbkami głosów osób, które zginęły. Dokonała jednak identyfikacji autorstwa większości wypowiedzi w stenogramie, na podstawie osobistej znajomości głosu niektórych osób, oraz kontekstu sytuacyjnego (w tym wypadku, opartego na znajomości standardowego podziału ról w załodze samolotu Tu-154M). Transkrypt został umieszczony w załączniku 8, tym samym, w którym opisał metodę uzyskania odsłuchiwanego nagrania jeden ze specjalistów.
(ii) Grupa audiologii (w osobie prof. fonologii) mająca przeanalizować wybrane fragmenty zapisów dźwięku, głównie pod kątem identyfikacji wypowiedzi osób trzecich (ze względu m.in na rozbieżne poprzednie wnioski co do obecności w kokpicie w ostatnich minutach przed katastrofą Dowódcy Sił Powietrznych). Wymienione są też analizy stanu emocjonalnego mówców. Wyniki opisane są w załączniku 9 do opinii kompleksowej ZB (zespołu biegłych) WPO. Z załączników nie wynika jasno jak grupy (i) i (ii) współpracowały ze sobą, jako że zał. 9 wymienia prace grupy odsłuchowej nie więcej niż raz, i vice versa.
Metody amerykańskie: Analiza przyczyn wypadku
W USA odsłuchuje CVR z wypadku lotniczego (oprócz spowodowanych przez terroryzm, jak 9/11) niezależna instytucja rządowa nie mająca odpowiednika w Polsce: National Transportation Security Board (NTSB, narodowa komisja d/s bezpieczeństwa transportu).
To więcej, niż tylko komisja badania wypadków lotniczych, zajmuje się bowiem wszelkimi wypadkami i sprawami transportu powietrznego, morskiego i naziemnego, włącznie z rurociągami. Początkowo podłączona pod ministerstwo transportu, została po 1974 roku wydzielona i uniezależniła się. W zarządzie zasiada 5 osób, z których nie więcej niż 3 mogą być z tej samej partii politycznej. Szefa nominuje prezydent a zatwierdza senat. Przy wypadkach lotniczych NTSB ściśle współpracuje z ministerstwem lotnictwa cywilnego (FAA, Federal Aviation Administration). Oprócz FAA, NTSB zwykle określa też inne strony dochodzenia, takie jak np.: piloci (zazwyczaj podejrzewani o sprawstwo przez producenta samolotu) i producent samolotu (zazwyczaj podejrzewany o sprawstwo przez pilotów). Interesy pilotów często reprezentowane są przez członka ich związku zawodowego.
NTSB pracuje bardziej formalnie i w oparciu o konkretne podręczniki dobrych praktyk, takie jak CVR Handbook (2007), niż to się dzieje w większości krajów europejskich. To może się brać stąd, że lotnictwo i ogólniej transport w USA są bardzo rozwinięte i liczne, co prowadzi też do bardzo wielu wypadków (140 tys. przeanalizowano w NTSB, wydając pon. 13 tys. rekomendacji zmian ustawodawstwa), które przy braku procedur standardowych trudno byłoby sprowadzić do wspólnego mianownika. Po drugie, w USA bardzo łatwo zostać oskarżonym o niewłaściwe postępowanie, stąd naturalne okazało się takie sformułowanie reguł odsłuchu CVR, które na etapie śledztwa komisji wyklucza, a w ew. późniejszych procesach sądowych bardzo ogranicza możliwość wytknięcia badającym zapisy wypadkowe specjalistom niewłaściwego prowadzenia prac, błędną metodologię czy wnioski. Taśmy lub kości pamięci CVR nigdy nie są przedstawiane publiczności. To może nastąpić tylko, jeśli w sądzie prawnik NTSB nie da sobie rady. Normalnie publikowane są tylko raporty wstępne i końcowe podsumowujące prace NTSB oraz w wielu ważniejszych wypadkach, stenogramy.
Zespół odsłuchujący CVR zawiera przedstawicieli wszystkich stron: związku pilotów, jeśli trzeba to związku zawodowego mechaników lotniczych, producenta statku powietrznego, przedstawicieli (śledczych i specjalistów) ministerstwa FAA. Liczebność zespołu zależy od epoki (dawniej bywało mniej odsłuchujących) i od rodzaju sprawy, ale z bazy danych widać, że typowo to 4-7 osób, włączając specjalistę-technika od CVR (komitet odczytuje materiały w swym laboratorium). Inaczej niż w wielu krajach, biegli zespołu zbierają się podobnie jak ławnicy amerykańscy, w jednym miejscu, w określonym czasie, i mają pracować tak długo, aż stworzą i podpiszą swój wspólny transkrypt. Jak nie zdążą jednego dnia, pracują następnego. Ale to nie trwa kilka miesięcy, jak u nas. Wątpię, żeby obecne odczyty ustępowały jakością amerykańskim, my tylko mamy chyba większą determinację żeby robić i poprawiać po sobie błędy. Mimo ewidentnie pospiesznej amerykańskiej analizy, nie jest ona powtarzana. Czytałem wiele raportów i transkryptów, ale nie pamiętam, by kiedykolwiek prowadzano powtórne odsłuchy nośników. Takie odsłuchy mógłby nakazać tylko sąd. Co do odszumiania, NTSB nie dzieli się zbyt wieloma szczegółami.
Przykład grupy odsłuchowej NTSB:
Typowym zdarzeniem, gdzie CVR był ważnym wskazaniem co się stało, czy zawinił człowiek czy technika, był wypadek Airbusa 320 US Airways, lot 1549, dn. 15 stycznia 2009 r. w Weehawken, NJ. Raport numer DCA09MA026, grupy d/s CVR pod przewodnictwem Douglasa P. Brazy, stworzony został w Waszyngtonie (siedzibie Vehicle Recorder Division, NTSB) bardzo szybko, bo 22 kwietnia, 2009. Członkami grupy odsłuchowej oprócz przewodniczącego pracującego dla NTSB byli:
2. Capt. Rudy Canto, Director, Flight Operations Technical, Airbus
3. Jeff Diercksmeier, Accident Investigation Team, US Airline Pilots Association
4. Capt. Chuck Pastene, Check Airman Flight Training, US Airways
5. Floyd James, Air Safety Investigator, Office of Accident Investigation, FAA
6. Andy Mihalchik, Program Mgr. Technical Pilot, Flight Operations Support, GE Transportation – Aircraft Engines (przedstawiciel producenta silników, ważnych w wypadku), oraz
7. Nicholas Marcou, zast. szefa działu dochodzeń francuskiego odpowiednika NTSB, Bureau d’Enquetes et d’Analyses (BEA)
Skład nieco inny, ale liczebność taka, jak w ostatnich odczytach WPO.
NTSB nie prosi o pomoc
Dlaczego, jak w tym przykładzie, NTSB nie korzysta w pracy nad CVR z opinii audiologów, fonologów, językoznawców, biometrów, specjalistów od automatycznej identyfikacji mówców i/lub transkrypcji komputerowej? Gdyż uważa, że nie są potrzebni. NTSB uważa, że ich techniczni specjaliści lotniczy nie tylko wystarczają, ale mogą też uzyskać bardziej sensowny odczyt. Co nie znaczy idealny. Opatruje więc swój stenogram ostrzeżeniem następującej, częściowo już wspomnianej przeze mnie treści:
Warning. Czytelników tego raportu uprzedza się, że transkrypcja taśmy CVR nie jest nauką ścisłą, lecz najlepszym z możliwych wynikiem pracy grupy dochodzeniowej NTSB. Transcrypt, albo jego część, jeśli będzie wyjęty z kontekstu, może wprowadzać w błąd. Powinien być używany łącznie z innymi dowodami zebranymi w dochodzeniu. Nie należy dochodzić do wniosków wyłącznie na podstawie transkryptu.
I po takim ostrzeżeniu, dostajemy na ogół transkrypt i zero nagrań audio. A w mniejszych sprawach nawet bywa, że żadnego transkryptu. Przynajmniej nie ma się wtedy o co kłócić, jak teraz, kiedy mamy tyle odczytów smoleńskich.
Badanie wypadków w Europie
W Europie i Kanadzie postępuje się podobnie jak w Ameryce, tylko praca komisji badania wypadków lotniczych takich jak francuska BEA, angielska AAIB, niemiecka BFU, czy kanadyjska TSB, jest trochę słabiej określona, opisana i skodyfikowana, niż w USA.
Opracowanie nagrań dźwiękowych dla potrzeb sądowych
Z jedności zasadniczych celów jak najlepszego odczytania treści rozmów w kokpicie nie wynika, iż podobne procedury do wyżej opisanych stosuje się przed sądem.
Systemy sądownictwa (i to różne, bo przecież system prawny w Polsce nie przypomina w szczegółach prawa angielskiego) mają swoje specyficzne wymagania i procedury wynikające z długiej i zagmatwanej historii. Sądy są w większości niesłychanie konserwatywne, w porównaniu z laboratoriami naukowymi, gdzie rozwija się metody DSP (digital signal processing, opracowania cyfrowego danych), jak też z komisjami badania wypadków. Aby uniknąć błędów prawniczych, sądy (sędziowie i ewentualni ławnicy) wymagają, by stosowane metody były dla nich zrozumiałe, jak też chcą mieć rękojmię 'właściwej' prawnie metody pracy z materiałem, aby móc przyjąć odczyty nagrań za dowód w sprawie. Dlatego czasami składają lepszą (być może) jakość odczytu na ołtarzu rutyny, nie dopuszczając jako dowód nowych metod, albo metod wcale nie nowych, ale odbiegających od stosowanych wcześniej w sprawach, których rozstrzygnięć nikt nie zdołał podważyć. Żalą się na to przedstawiciele cywilizacji technicznej pragnącej postępu w metodyce badań - inżynierowie i fonolodzy, tacy jak jak Maher (2009).
Czy w Polsce może być to problemem w przypadku Smoleńska, jeśli naturalnie dojdzie do jakichś spraw z użyciem CVR? Nie wiem. Metodologia krakowskiego IES jest w każdym razie podobna bardziej do najbardziej konserwatywnych praktyk sądów USA, niż do typowych badań komisji wypadkowych na świecie. Te ostatnie nie wymierzają sprawiedliwości, tylko obsesyjnie dbają o bezpieczeństwo lotnictwa. Mając ten ważny cel są bardziej otwarte na nowości techniczne. Muszą się składać z licznych, wysoko wykwalifikowanych specjalistów lotniczych. Sądy nie mają natomiast najmniejszego obowiązku rozumieć szczegółów metod, jakie ich nieliczni biegli stosują.
Tradycyjnie, było tak: sąd rozstrzygał na podstawie opinii biegłych, którzy mieli być wysoko wykwalifikowani, powinni być naukowcami godnymi zaufania. W sprawie Frye przeciw Stanom Zjednoczonym, uznano w 1923 r., że dowody naukowe powinny opierać się na wypróbowanych, ogólnie przyjętych metodach znanych danej społeczności naukowej. I tylko to sąd sprawdzał - czy jest konsensus, a nie to, czy metoda jest najlepsza z możliwych w danym przypadku.
Dla przykładu, jeśli wszycy by próbkowali CVR z częstotliwością 11 kHz, to tak miało być aż do momentu, kiedy większość naukowców zmieni zdanie. Oczywiście to nonsens, który skorygowano w roku 1993. Sąd Najwyższy USA w sprawie Daubert kontra Merell Dow Pharmaceuticals Inc. orzekł wtedy, że ponieważ postęp w nauce polega zazwyczaj na pojawieniu się poglądów mniejszości, nie trzeba szukać konsensusu większości społeczności naukowej. Wystarczy pozytywna opinia paru naukowców recenzujących, uczestniczących w peer review. Naturalnie, zasady nauki leżące u podstaw metody muszą być niekontrowersyjne (nie chcieli podziwiać map poszukiwacza zaginionej brzozy prof. Cieszewskiego, dedukcji wybuchów z liczby odłamków większej niż trzy dra Szuladzińskiego, ani cyfrowo-pancernego tupolewa prof. Biniendy, lądującego na plecach nie rozpadając się, ba, nie tracąc nawet statecznika pionowego). Metoda powinna być powtarzalna i weryfikowalna, oraz mieć ocenę prawdopodobieństwa błędu (zwłaszcza, jeśli chodzi o identyfikacje osób). Takie wymagania dużo łatwiej spełnić, niż dawniej, jeśli metoda ma jakieś elementy nowatorskie. Od 1999 r. zniesiono wymaganie by ekspert był naukowcem, może być inżynierem dźwięku lub innym specjalistą (sprawa Kumho Tire przeciw Carmichel; por. Maher 2009).
W końcowym rozrachunku, o tym dokładnie jak określić kryteria dopuszczalności dowodu teraz decyduje dziś raczej sąd/sędzia, a nie naukowcy-eksperci. Ma to pewne wady! Sędziowie są różni. W każdym razie, Europa też patrzy na Amerykę i stara się rozpatrywać sprawy bardziej indywidualnie, nie nalegając na plebiscyty popularności danej metody wsród naukowców. Przykładowo, sprawa Dauberta odcisnęła piętno na nowych rekomendacjach Angielskiej Narodowej Fundacji Badań oraz Komisji Prawa UK i oczekuje się, że będzie miała wielki wpływ na praktykę fonetyki sądowej w Anglii (A. Eriksson, str. 64 w Neustein & Patil 2012).
Takie jest tło. A jeśli dojdzie do smoleńskich spraw sądowych, zobaczymy czy potoczą się po dawnemu (Frye'rsku) czy po nowemu (Daubertowsku). Prawo mamy harmonizować z Unią, ale zachowując swoje idosynkrazje (nie obrażając nikogo; mamy do tego.. prawo). Pewne metody, takie jak dodawanie dokładnie zsynchronizowanych danych, dadzą się prosto i przekonująco streścić przed sądem. Na koniec, w ewentualnych procesach smoleńskich, autentyczność taśmy CVR nie będzie trudna do ustalenia sądowego, ponieważ tę pracę wykonał dobrze KIES.
Sezon na sybilanty
W przypadku pracy WPO, zasadnicza część innowacji w odczytach CVR to żadna nowość, tylko po prostu uniknięcie wandalizmu danych przez zbyt niską częstotliwość próbkowania, co jest bardzo łatwe do wykazania. Są niestety specjaliści, nawet zagraniczni biegli sądowi, którzy nie doceniają jak wysoko na skali częstotliwości żyją niektóre głoski (liczne polskie sybilanty ź, z, ś, ć, c, dź), i nie wiedzą, że analogowe systemy audio są w stanie je zapisać i odtworzyć. Sybilanty mieszkają na stałe w zakresie 4-12 kHz, ale widuje się je i na jeszcze wyżej położonych terenach widma. Ich nisza, przestrzeń życiowa, jest przez niektórych okrutnych dźwiękowców brutalnie wycinana.
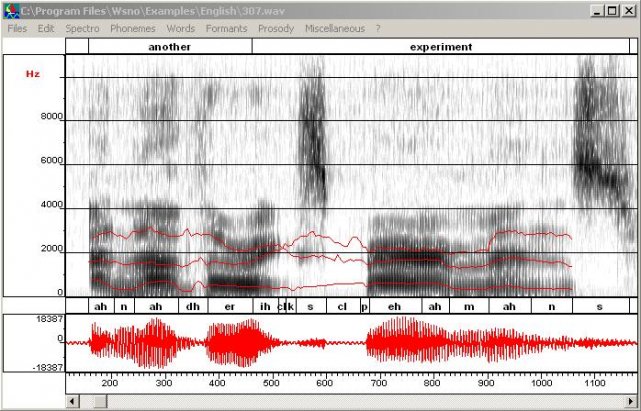 Niektóre głoski i ich formanty • www.loria.fr
Niektóre głoski i ich formanty • www.loria.fr
Popatrzmy teraz na dwa poniższe rysunki. Na obu skala pionowa częstotliwości jest logarytmiczna. Pierwszy to analiza widmowa zmiksownych kanałów mikrofonowego i radiowych z prezentacji MAK CVR PLF 101, mniej więcej od wypowiedzi "Dochodź wolniej!" do kilku pierwszych dzwonków sygnalizacji bliższej radiolatarni (BRL). Drugi to mniej więcej ten sam fragment nagrania CVR, pokazany w Zał. 8 publikacji WPO linkowanej w porzednim felietonie jako rys. 41. To zapis wyłącznie kanału nr 3, z trzech mikrofonów, z próbkowaniem 96 kHz i odszumianiem. Ponieważ opis osi nie jest w materiałach WPO czytelny (skoro taki już jest ten rysunek, może warto udostępnić nie coś, co wygląda na skan, a orginalny PDF), skopiowałem kilka wartości poza prawą ramą rysunku, od 1.5 do 15 kHz. Też użyłem za małej czcionki i wyszły mi nieczytelne (radzę użyć CTRL +)
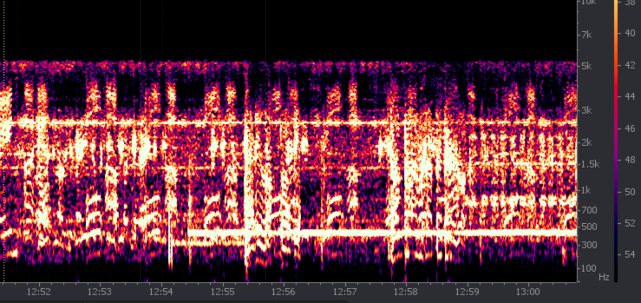 widmo z próbkowanego z częstościa 11 kHz zapisu CVR • MAK
widmo z próbkowanego z częstościa 11 kHz zapisu CVR • MAK
O ile próbkowanie 11 kHz daje obcięcie jak nożem do zera składowych harmonicznych dźwięku powyżej 5.5 kHz, o tyle nowy odczyt zawiera, jak widać, bardzo wiele fonemów zdominowanych przez wysokie składowe, od 5 do 12 kHz. Leżą one powyżej strzałek opisanych jako "odchodzimy" i "dobrze chłopaki", a poniżej strzałek podpisanych odliczaną wysokością.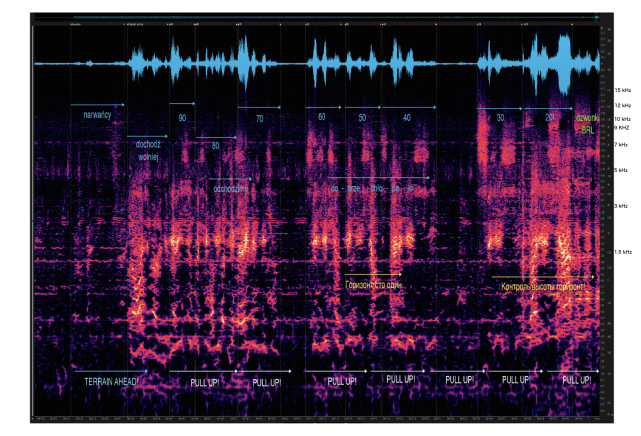 widmo tego samego fragmentu CVR próbkowanego z f=96 kHz • WPO
widmo tego samego fragmentu CVR próbkowanego z f=96 kHz • WPO
Te właśnie dźwięki z górnych 35-40% drugiego rysunku są maltretowane nie do poznania w standardowych nagraniach próbkowanych z f=11 kHz, co zdaje się być niestety wartością f zgodną z konsensusem europejskim. Zarówno Rosjanie, jak i Anglicy w znanym laboratorium prof. Petera Frencha, sądzili, że można używać tej niskiej częstotliwości. Wielka pomyłka. W istocie, jakość konwersji analogowo-cyfrowej jest główną przyczyną rozbieżności pomiędzy transkryptami CLKP i KIES z jednej strony, a nowym tekstem WPO z drugiej, we fragmentach takich jak ten przykładowy, gdy padają pełne sybilantów słowa:
stenogram MAK:
i klapy trzydzieści sześć,
dwa osiem zero,
(niezroz.)
stenogram CLKP/KBWLLP:
do klapek trzydzieści sześć,
mamy dwa osiem zero
stenogram IES:
(Na klapach (?) trzydzieści sześć,
dwa osiem (metra (?))
(niezr.)
stenogram ZB WPO:
na klapach trzydzieści sześć,
mamy dwa osiem zero,
ćśś..ćśś,
na przykład! (niezr.)
Dawne odczyty nie mogły zrobić wiele więcej, niż zapisać "(niezr.)" lub (?) w wielu miejscach. Teraz, z bardziej poprawnymi sybilantami, czytelność została zwiększona. Niezrozumiałość wynikała też z większego flutteru taśmy, który obróbka cyfrowa nieco zredukowała. To chyba najlepsza ilustracja zalet porządnej analizy danych, a na polu prawnym - argument za liberalnymi zasadami dopuszczalności dowodów, już stosowanymi w wielu krajach.
Identyfikacja osób w nagraniu
Jak widzieliśmy, komisja NTSB nie zatrudnia zazwyczaj nikogo z występujących w sądzie specjalistów (jezykoznawców, stengrafów, fonetyków). Mimo to, w transkrypcie bez zbędnych usprawiedliwień pojawia się identyfikacja funkcji lotniczej mówiącego: to mówi kapitan, to drugi pilot, a to kontroler lotu lub stewardesa. Skąd członkowie amerykańskiej grupy odsłuchowej to wiedzą? Z kontekstu sytuacyjnego, stosując metodę auralno-percepcyjną (odsłuchową). To samo co amerykańska agencja, lecz wzmocnione powołaniem do pracy w grupie odsłuchowej osoby lub osób znających wcześniej niektóre ofiary wypadku, zrobiła polska prokuratura wojskowa.
Ogólnie, można powiedzieć, że o ile taki wysoki standard jest przyjęty w pracy komisji badania wypadków, o tyle do celów sądowych to może nie wystarczyć, bo historycznie podyktowane wymagania formalne mogą nie być spełnione. Wtedy zatrudnia się specjalistę audiologa, potrafiącego dokonać porównania wielu aspektów nagrania dowodowego i próbki głosu uzyskanej najczęściej z mediów lub archiwów rodzinnych: formanty (częstotliwości rezonansowe, od podstawowego F0 do wyższych harmonicznych F1, F2, ..., oraz ich stosunki liczbowe), rozkłady statystyczne formantów, ich szerokość i kurtoza (asymetria). Jest to trudna praca, ponieważ do pewnego stopnia to, co konfuduje komputery, także przeszkadza poprawnie rozróżniać lub identyfikować mówcę ludziom: różny kontekst i różna jakość nagrania. Inaczej mówi dana osoba w wywiadzie radiowym, inaczej na urodzinach dziecka, a inaczej na podejściu precyzyjnym we mgle, obserwując wskaźnik wysokości. A samo nagranie jest kompletnie innej jakości, stąd zawsze jest pytanie, czy wynik identyfikacji jest poprawny, czy fałszywie pozytywny (albo negatywny).
Praktyka sądowa borykała się od dawna z problemem pewności identyfikacji mówiących. W jednym z najsłynniejszych procesów, w 1935 r. , w sprawie uprowadzenia i zabójstwa dziecka Charlesa Lindbergha, sławny pilot zaświadczył, że głos podejrzanego jest tym samym głosem, który słyszał przy przekazywaniu okupu. Do dziś jest bardzo wiele wątpliwości, czy właściwy człowiek został posadzony na krześle elektrycznym. To była epoka przed-instrumentalna. Ale można powiedzieć też wiele złego o praktyce sądowej w latach 50-tych do 70-tych, kiedy pojawiły się możliwości techniczne wykreślania i wizualnego porównywania spektrogramów głosu ludzkiego. Niesłusznie porównywano je do odcisków palców (te drugie są znacznie bardziej niezawodne, co ignorowano, nazywając tę metodę 'voiceprinting' na podobieństwo fingerprinting). Tytułowy, niezaszumiony, czarno-biały spektrogram to taki domniemany 'odcisk głosu'. Podejrzewam, że zanim doceniono zmienność głosu ludzkiego oraz trudności odsłuchu mocno zaszumionych nagrań, wydano na świecie wiele niesłusznych wyroków.
Później okazało się, jak wiele rzeczy wpływa na widmo głosu i tempo wypowiedzi, a nawet to, że płeć identyfikującego jest nieobojętna (dla nieco lepszego odczytu, powinna być ta sama, co identyfikowanego). Obecnie nie ma już na świecie szeroko rozprzestrzenionego problemu z nadmierną ufnością w pewność identyfikacji mówców - za wyjątkiem osób oglądających fikcyjne laboratoria w serialu telewizyjnym "CSI" (crime scene investigation).
Zwłaszcza w nagraniach starego systemu MARS trudno marzyć o 100% pewnej identyfikacji osób trzecich, oddalonych od mikrofonów. Trudno jest w takim przypadku jasno sprecyzować ich formanty, gdyż po pierwsze osoby trzecie nie za wiele i nie za głośno mówią, próbki ich głosu są za krótkie do analizy statystycznej, a poza tym to co mówią konkuruje z równie głośnym szumem o zmiennej, pulsującej charakterystyce. Osoby te stały 10.04.10 u wejścia do kokpitu. Dochodziły też nieokresowe, wycinające czasami wysokie tony dropouty na taśmie. Nowe analizy dały taki rezultat, że gen. Błasik mógł być obecny (m.in. z kontekstu sytuacyjnego), ale nie można tego z dużą dozą pewności potwierdzić. Ten wynik zgodny jest z literaturą przedmiotu, cytowaną przez autorkę opinii, prof. G. Demenko.
Mimo trudności, sądy chcą zawsze poznać tożsamość anonimowych mówców, a sędziom wydaje się nieraz, że analiza fonetyczna z wizualizacją formantów, poparta tradycją lub długą listą prac naukowych jest pewniejsza, niż odsłuch dokonanany przez ucho i mózg człowieka. To może być prawdą tylko w odniesieniu do porównania głosów nagranych w odpowiednich warunkach. Do stenografii i/lub rozpoznawania fraz słabo słyszalnych wsród szumu i zakłóceń, ucho+mózg nadają się lepiej. Nasz adaptywny organ rozumie przy tym dużo lepiej osoby znajome niż nieznajome (nieznany wcześniej głos włącza wg. najnowszych badań odmienny tryb działania mózgu, głos jest analizowany od podstaw, a nie jak w przypadku osoby znajomej - szybko kojarzony z pamiętanym wzorcem formantów i ich zmienności). Jest wiele wskazówek, którymi mózg kieruje się rozpoznając czyjś głos, ale nie umiemy jeszcze tych umiejętności opisać, zwłaszcza algorytmicznie. Zaś oglądanie widma fourierowskiego (w dość dowolny sposób wykreślonego) jak to potrafią robić fonolodzy, to trochę ryzykowne przerzucanie całej trudnej pracy zmysłu słuchu na wzrok, który nie został raczej stworzony do identyfikacji mówców. Co więc wybrać?
I tu dochodzimy do konkluzji: a może to, co zrobiła prokuratura wojskowa, zlecając obie metody identyfikacji (rozpoznanie czysto słuchowe i fonetyczną analizę widmową) "nie było takie głupie"? [20-letni Wolfgang Pauli w publicznym komentarzu o tym, co powiedział chwilę wcześniej prof. Albert Einstein].
___________________________________
Literatura:
• CVR Handbook for Aviation Accident Investigation (NTSB), 2007, Washington, DC
• Loizou, Philipos C., 2013, Speech Enhancement, CRC Press, 689 stron.
• Maher R. C., Audio Forensic Examination IEEE Signal Processing Magazine, INE, 84-94, MARCH 2009
• Neustein, Amy & Patil, Hemant, 2012, Forensic Speaker Recognition. Law enforcement and counter-terrorism, Springer, 540 stron. (Link do większości rozdziałów książki)
Brak komentarzy:
Prześlij komentarz